开始
对长期做业务开发的同学来说,写代码可能是件容易的事情,也可能是件很麻烦的事情。说容易,主要是因为需求基本上是CRUD(增、查、改、删),再复杂的业务,也可以这么做(有点事务脚本的意思)来实现需求。说复杂或麻烦呢,主要是考虑如何分工,如果划分职责,把package分清楚,可能就是一件很繁琐和有挑战的事情。
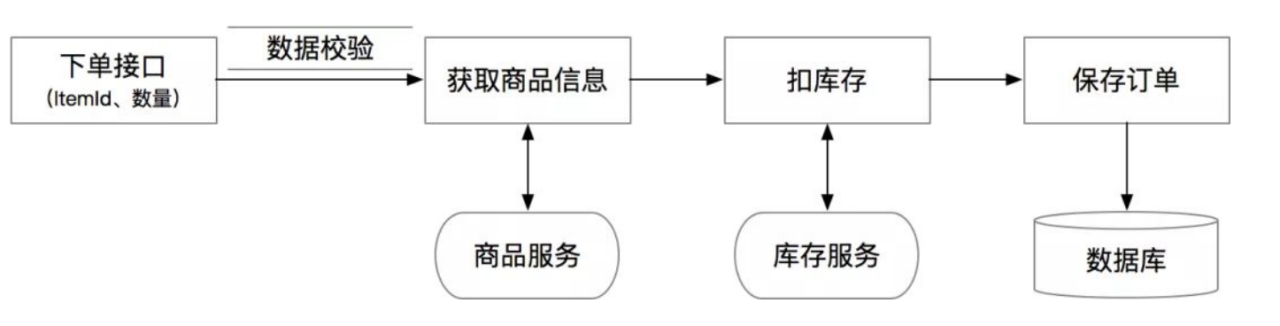
拿下单业务来说,假设我们在做一个checkout接口,需要做各种校验、查询商品信息、调用库存服务扣库存、然后生成订单:
常见写法,代码如下:
1 |
|
为什么这种典型的流水账代码在实际应用中会有问题呢?其本质问题是违背了SRP(Single Responsbility Principle)单一职责原则。这段代码里混杂了业务计算、校验逻辑、基础设施、和通信协议等,在未来无论哪一部分的逻辑变更都会直接影响到这段代码,长期当后人不断的在上面叠加新的逻辑时,会造成代码复杂度增加、逻辑分支越来越多,最终造成bug或者没人敢重构的历史包袱。
面对这样的问题,如何处理?
主要的几个步骤分为:
分离出独立的Interface接口层,负责处理网络协议相关的逻辑
从真实业务场景中,找出具体用例(Use Cases),然后将具体用例通过专用的Command指令、Query查询、和Event事件对象来承接
分离出独立的Application应用层,负责业务流程的编排,响应Command、Query和Event。每个应用层的方法应该代表整个业务流程中的一个节点
Interface接口层(Client)
在实际做业务的过程中,特别是当支撑的上游业务比较多时,刻意去追求接口的统一通常会导致方法中的参数膨胀,或者导致方法的膨胀。举个例子:假设有一个宠物卡和一个亲子卡的业务公用一个开卡服务,但是宠物需要传入宠物类型,亲子的需要传入宝宝年龄。
1 | // 可以是RPC Provider 或者 Controller |
可以看出来,无论是怎么操作,都有可能导致CardService这个服务未来越来越难以维护,方法越来越多,一个业务的变更有可能会导致整个服务/Controller的变更,最终变得无法维护
一个Interface层的类应该是“小而美”的,应该是面向“一个单一的业务”或“一类同样需求的业务”,需要尽量避免用同一个类承接不同类型业务的需求
基于上面的这个规范,可以发现宠物卡和亲子卡虽然看起来像是类似的需求,但并非是“同样需求”的,可以预见到在未来的某个时刻,这两个业务的需求和需要提供的接口会越走越远,所以需要将这两个接口类拆分开:
1 | public interface PetCardService { |
好处是符合了Single Responsibility Principle单一职责原则,也就是说一个接口类仅仅会因为一个(或一类)业务的变化而变化。建议当一个现有的接口类过度膨胀时,可以考虑对接口类做拆分,
拆分原则和SRP一致。
如果按照这种做法,会不会产生大量的接口类,导致代码逻辑重复?答案是不会,因为在DDD分层架构里,接口类的核心作用仅仅是协议层,每类业务的协议可以是不同的,而真实的业务逻辑会沉淀到应用层。也就是说Interface和Application的关系是多对多的:
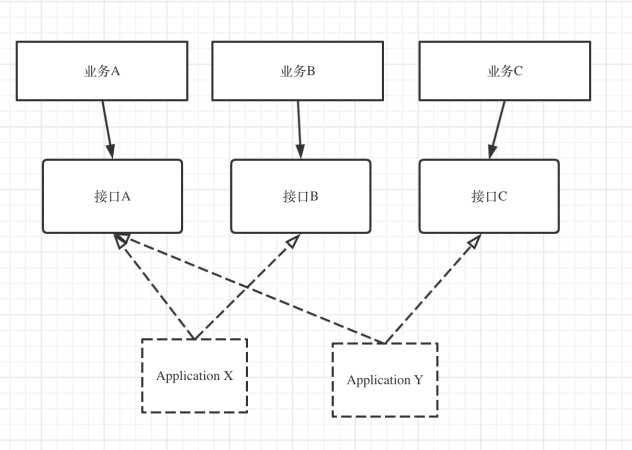
总结interface(Client):
职责:主要负责承接网络协议的转化、Session管理等
接口数量:避免所谓的统一API,不必人为限制接口类的数量,每个/每类业务对应一套接口即可,接口参数应该符合业务需求,避免大而全的入参
接口出参:统一返回Result
异常处理:应该捕捉所有异常,避免异常信息的泄漏。可以通过AOP统一处理,避免代码里有大量重复代码。
Application层(App)
组成
Application层的几个核心类:
ApplicationService应用服务:最核心的类,负责业务流程的编排,但本身不负责任何业务逻辑
DTO Assembler:负责将内部领域模型转化为可对外的DTO
Command、Query、Event对象:作为ApplicationService的入参
返回的DTO:作为ApplicationService的出参
Application层最核心的对象是ApplicationService,它的核心功能是承接“业务流程“。但是在讲ApplicationService的规范之前,要先重点的讲几个特殊类型的对象,即Command、Query和Event。
CEQ
从本质上来看,这几种对象都是Value Object,但是从语义上来看有比较大的差异:
Command指令:指调用方明确想让系统操作的指令,其预期是对一个系统有影响,也就是写操作。通常来讲指令需要有一个明确的返回值(如同步的操作结果,或异步的指令已经被接受)。
Query查询:指调用方明确想查询的东西,包括查询参数、过滤、分页等条件,其预期是对一个系统的数据完全不影响的,也就是只读操作。
Event事件:指一件已经发生过的既有事实,需要系统根据这个事实作出改变或者响应的,通常事件处理都会有一定的写操作。事件处理器不会有返回值。这里需要注意一下的是,Application层的Event概念和Domain层的DomainEvent是类似的概念,但不一定是同一回事,这里的Event更多是外部一种通知机制而已。
总结一下:
| Command | Query | Event | |
|---|---|---|---|
| 语意 | “希望”能触发的操作 | 各种条件查询 | 已经发生的事情 |
| 读/写 | 写 | 只读 | 一般是写 |
| 返回值 | DTO或Boolean | DTO或Collection | Void |
为什么要用CQE对象?
通常在很多代码里,能看到接口上有多个参数,比如上文中的案例:
1 | Result<OrderDO> checkout(Long itemId, Integer quantity); |
如果需要在接口上增加参数,考虑到向前兼容,则需要增加一个方法:
1 | Result<OrderDO> checkout(Long itemId, Integer quantity); |
或者常见的查询方法,由于条件的不同导致多个方法:
1 | List<OrderDO> queryByItemId(Long itemId); |
可以看出来,传统的接口写法有几个问题:
接口膨胀:一个查询条件一个方法
难以扩展:每新增一个参数都有可能需要调用方升级
难以测试:接口一多,职责随之变得繁杂,业务场景各异,测试用例难以维护
还有另外一个最重要的问题是:这种类型的参数罗列,本身没有任何业务上的”语意“,只是一堆参数而已,无法明确的表达出来意图。
CQE规范
在Application层的接口里,强力建议的一个规范是:
规范:ApplicationService的接口入参只能是一个Command、Query或Event对象,CQE对象需要能代表当前方法的语意。唯一可以的例外是根据单一ID查询的情况,可以省略掉一个Query对象的创建
按照上面的规范,实现案例是:
1 | public interface CheckoutService { |
这个规范的好处是:提升了接口的稳定性、降低低级的重复,并且让接口入参更加语意化。
CQE vs DTO
从上面的代码能看出来,ApplicationService的入参是CQE对象,但是出参却是一个DTO,从代码格式上来看都是简单的POJO对象,那么他们之间有什么区别呢?
- CQE:CQE对象是ApplicationService的输入,是有明确的”意图“的,所以这个对象必须保证其“正确性”。
- DTO:DTO对象只是数据容器,只是为了和外部交互,所以本身不包含任何逻辑,只是贫血对象。
但可能最重要的一点:因为CQE是“意图”,所以CQE对象在理论上可以有“无限”个,每个代表不同的意图;但是DTO作为模型数据容器,和模型一一对应,所以是有限的。
CEQ验证
CQE作为ApplicationService的输入,必须保证其正确性,那么这个校验是放在哪里呢?
在最早的代码里,曾经有这样的校验逻辑,当时写在了服务里:
1 | if (itemId <= 0 || quantity <= 0 || quantity >= 1000) { |
这种代码在日常非常常见,但其最大的问题就是大量的非业务代码混杂在业务代码中,很明显的违背了单一职责原则。但因为当时入参仅仅是简单的int,所以这个逻辑只能出现在服务里。现在当入参改为了CQE之后,我们可以利用java标准JSR303或JSR380的Bean Validation来前置这个校验逻辑。
规范:CQE对象的校验应该前置,避免在ApplicationService里做参数的校验。可以通过JSR303/380和Spring Validation来实现
前面的例子可以改造为:
1 | // Spring的注解 |
这种做法的好处是,让ApplicationService更加清爽,同时各种错误信息可以通过Bean Validation的API做各种个性化定制。
避免复用CQE
因为CQE是有“意图”和“语意”的,我们需要尽量避免CQE对象的复用,哪怕所有的参数都一样,只要他们的语意不同,尽量还是要用不同的对象。
ApplicationService
ApplicationService负责了业务流程的编排,是将原有业务流水账代码剥离了校验逻辑、领域计算、持久化等逻辑之后剩余的流程,是“胶水层”代码。
参考一个简易的交易流程:

在这个案例里可以看出,交易这个领域一共有5个用例:下单、支付成功、支付失败关单、物流信息更新、关闭订单。这5个用例可以用5个Command/Event对象代替,也就是对应了5个方法。
三种ApplicationService常见的组织形态(Bad Case):
1.复杂的业务流程会导致一个类的方法过多,有可能代码量过大
1 | public interface CheckoutService { |
2.化整为零:通过增加独立的CommandHandler、EventHandler来降低一个类中的代码量:
1 |
|
3.事件总线:通过CommandBus、EventBus,直接将指令或事件抛给对应的Handler,EventBus比较常见
1 | // 在这里框架通常可以根据接口识别到这个负责处理PaymentReceivedEvent |
这种做法可以实现Interface层和某个具体的ApplicationService或Handler的完全静态解耦,在运行时动态dispatch,做的比较好的框架如AxonFramework。虽然看起来很便利,但是根据我们自己业务的实践和踩坑发现,当代码中的CQE对象越来越多,handler越来越复杂时,运行时的dispatch缺乏了静态代码间的关联关系,导致代码很难读懂,特别是当你需要trace一个复杂调用链路时,因为dispatch是运行时的,很难摸清楚具体调用到的对象。现在已经不建议这么做了。
Application Service 是业务流程的封装,不处理业务逻辑
虽然之前曾经无数次重复ApplicationService只负责业务流程串联,不负责业务逻辑,但如何判断一段代码到底是业务流程还是逻辑呢?举个之前的例子,最初的代码重构后:
1 |
|
判断是否业务流程的几个点:
不要有if/else分支逻辑:也就是说代码的Cyclomatic Complexity(循环复杂度)应该尽量等于1
通常有分支逻辑的,都代表一些业务判断,应该将逻辑封装到DomainService或者Entity里。但这不代表完全不能有if逻辑,比如,在这段代码里:
1
2
3
4boolean withholdSuccess = inventoryService.withhold(cmd.getItemId(), cmd.getQuantity());
if (!withholdSuccess) {
throw new IllegalArgumentException("Inventory not enough");
}虽然CC > 1,但是仅仅代表了中断条件,具体的业务逻辑处理并没有受影响。可以把它看作为Precondition。
不要有任何计算
在最早的代码里有这个计算:1
2
3// 5)领域计算
Long cost = item.getPriceInCents() * quantity;
order.setTotalCost(cost);通过将这个计算逻辑封装到实体里,避免在ApplicationService里做计算
1
2
3
4
5
6
7
8
9
10
11public class Order {
private Long itemUnitPrice;
private Integer count;
// 把原来一个在ApplicationService的计算迁移到Entity里
public Long getTotalCost() {
return itemUnitPrice * count;
}
}
order.setItemUnitPrice(item.getPriceInCents());
order.setCount(cmd.getQuantity());一些数据的转化可以交给其他对象来做
比如DTO Assembler,将对象间转化的逻辑沉淀在单独的类中,降低ApplicationService的复杂度
OrderDTO dto = orderDtoAssembler.orderToDTO(savedOrder);
常用的ApplicationService“套路”
准备数据:包括从外部服务或持久化源取出相对应的Entity、VO以及外部服务返回的DTO。
执行操作:包括新对象的创建、赋值,以及调用领域对象的方法对其进行操作。需要注意的是这个时候通常都是纯内存操作,非持久化。
持久化:将操作结果持久化,或操作外部系统产生相应的影响,包括发消息等异步操作。
DTO Assembler(一般用MapStruct)
一个经常被忽视的问题是 ApplicationService应该返回 Entity 还是 DTO?这里提出一个规范,在DDD分层架构中:
ApplicationService应该永远返回DTO而不是Entity
为什么呢?
构建领域边界:ApplicationService的入参是CQE对象,出参是DTO,这些基本上都属于简单的POJO,来确保Application层的内外互相不影响。
降低规则依赖:Entity里面通常会包含业务规则,如果ApplicationService返回Entity,则会导致调用方直接依赖业务规则。如果内部规则变更可能直接影响到外部。
通过DTO组合降低成本:Entity是有限的,DTO可以是多个Entity、VO的自由组合,一次性封装成复杂DTO,或者有选择的抽取部分参数封装成DTO可以降低对外的成本。
结合之前的Data Mapper,DTO、Entity和DataObject之间的关系如下图:
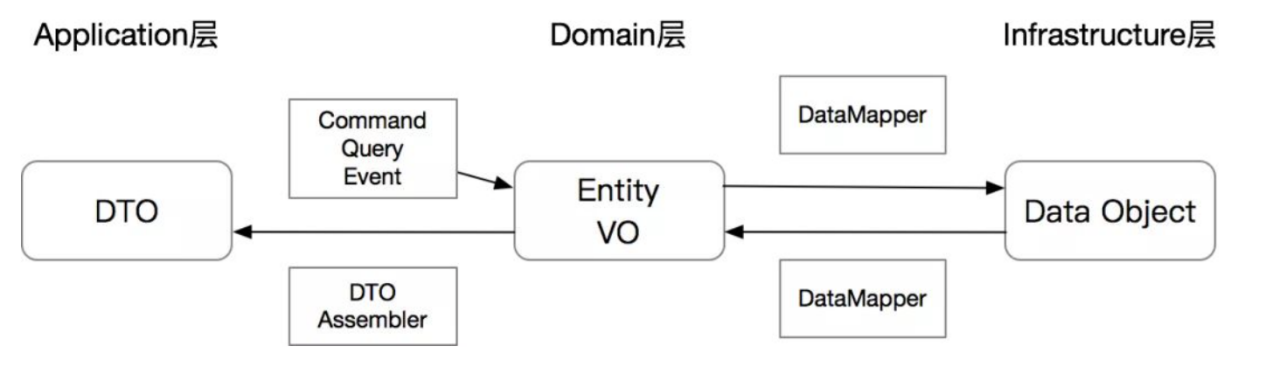
总结:
入参:具像化Command、Query、Event对象作为ApplicationService的入参,唯一可以的例外是单ID查询的场景。
CQE的语意化:CQE对象有语意,不同用例之间语意不同,即使参数一样也要避免复用。
入参校验:基础校验通过Bean Validation api解决。Spring Validation自带Validation的AOP,也可以自己写AOP。
出参:统一返回DTO,而不是Entity或DO。
DTO转化:用DTO Assembler负责Entity/VO到DTO的转化。
异常处理:不统一捕捉异常,可以随意抛异常。
Anti-Corruption Layer防腐层
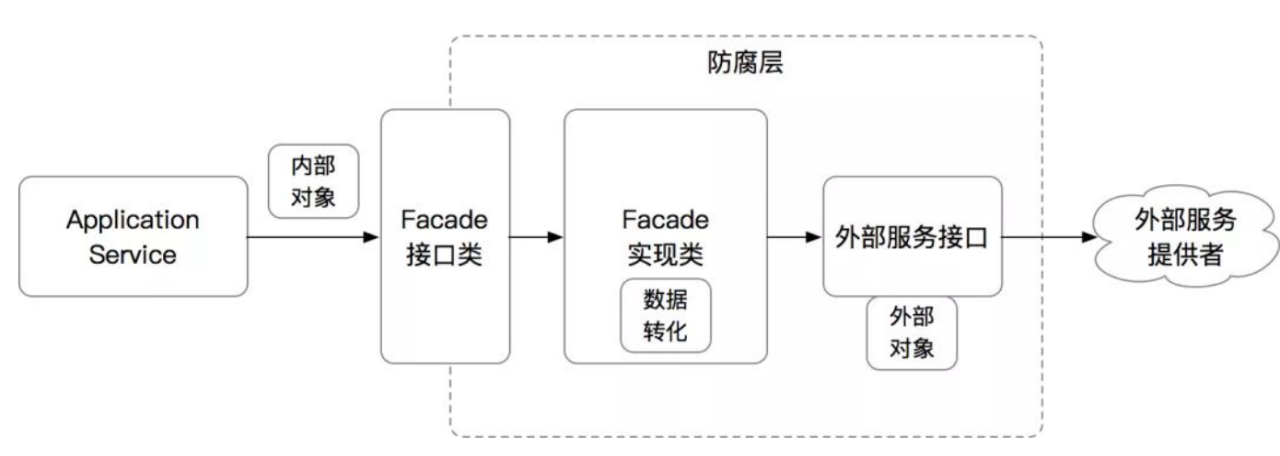
ACL防腐层的简单原理如下:
对于依赖的外部对象,我们抽取出所需要的字段,生成一个内部所需的VO或DTO类
构建一个新的Facade,在Facade中封装调用链路,将外部类转化为内部类
针对外部系统调用,同样的用Facade方法封装外部调用链路
无防腐层的情况:

有防腐层的情况:
项目组织结构
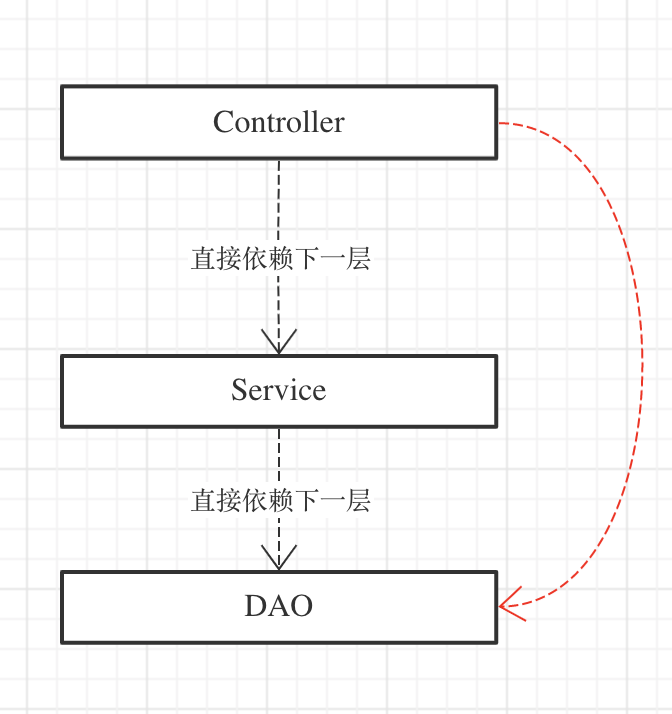
三层架构
主要特点
- 方便
- 灵活
- 上手快(“效率高”)
架构
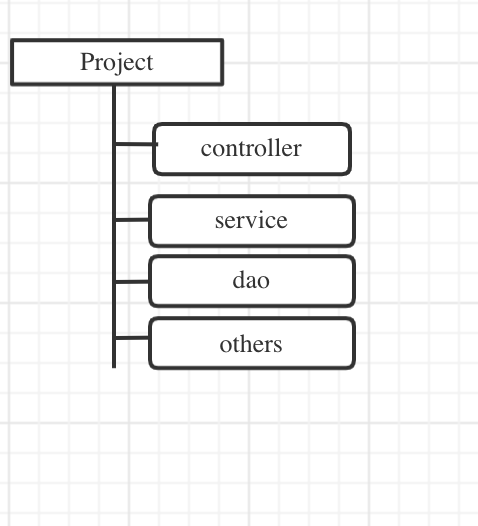
项目结构
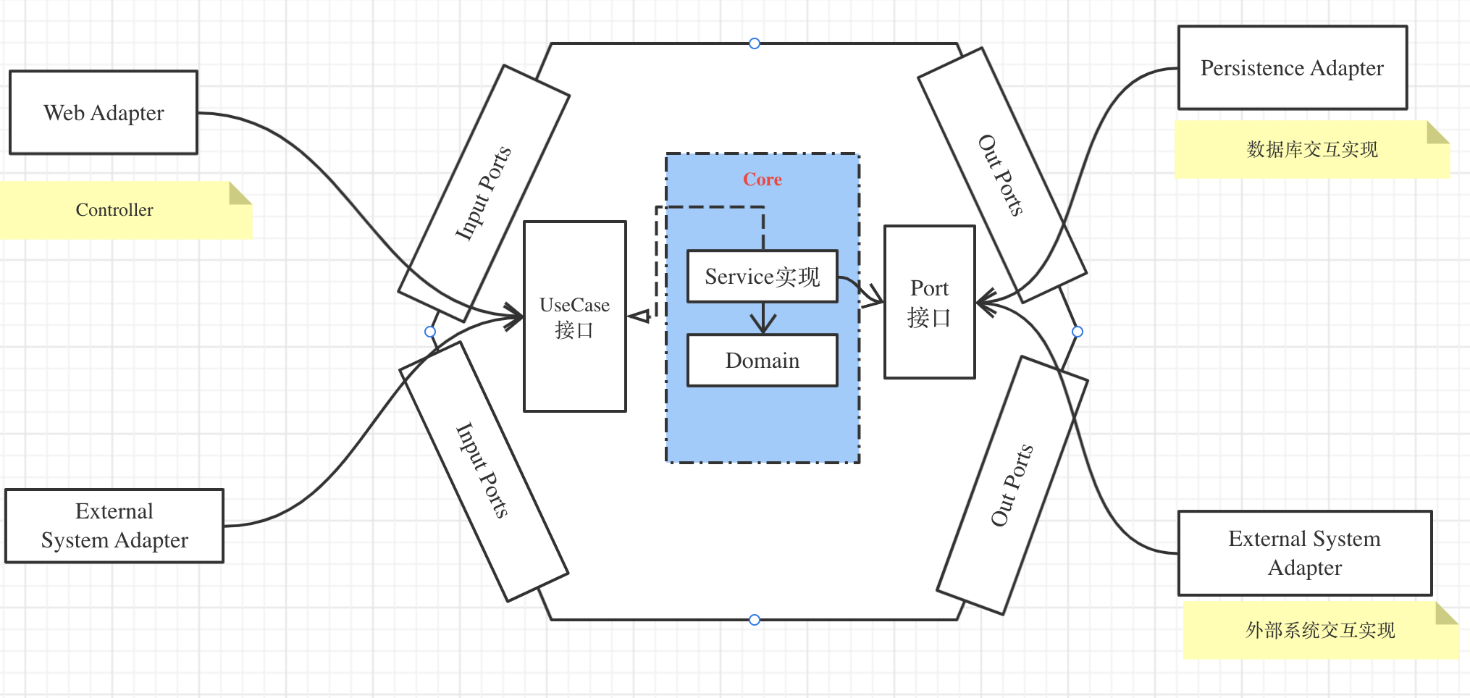
六边形架构
主要特点
- 业务内聚
- 依赖倒置
- 面向接口
架构
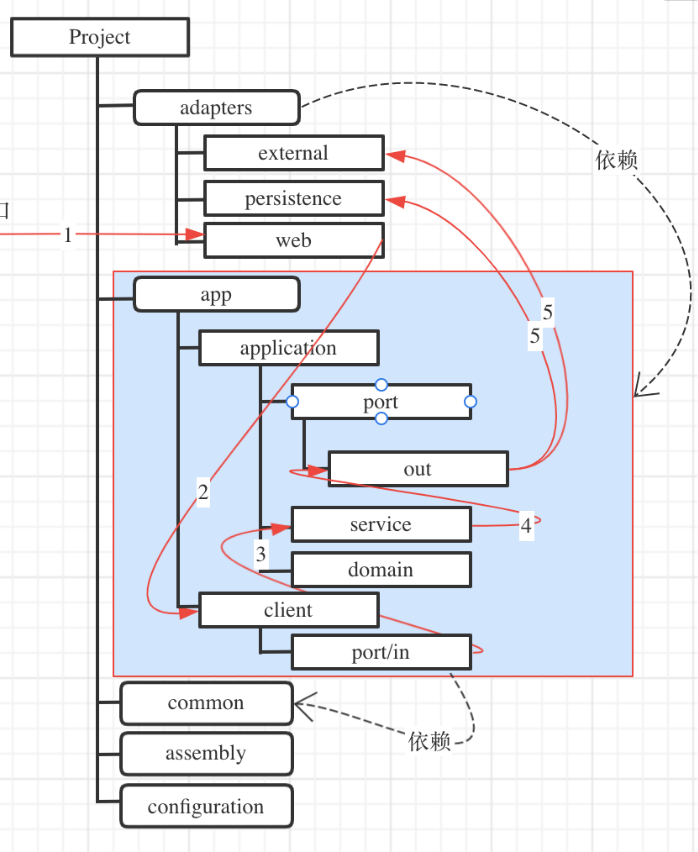
项目结构
适合自己的
根据业务场景(大环境,小环境),个性化适合业务领域的结构!
错误码
B1234567890;E1234567890
为什么要有错误码?
谁的错?错在哪?
降低沟通成本
快速定位问题
如何设计
HTTP的响应码
- 200 - 请求成功
- 301 - 资源(网页等)被永久转移到其它URL
- 404 - 请求的资源(网页等)不存在
- 500 - 内部服务器错误
| 分类 | 分类描述 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
腾讯小程序
| 错误代码 | 描述 | 原因 | 解决方案 |
|---|---|---|---|
| NO_AUTH | 没有该接口权限 | 1. 用户账号被冻结,无法付款 | 请根据具体的错误返回描述做对应处理,如返回描述不够明确,请参考此处的错误原因做排查。 |
| AMOUNT_LIMIT | 金额超限 | 1. 被微信风控拦截,最低单笔付款限额调整为5元。 | 目前最低付款金额为1元,最高10万元,请确认是否付款金额超限。 |
Twitter/Facebook
| 错误码 | 类型 | 描述 |
|---|---|---|
| 192 | OAuthException | Missing redirect_uri parameter. |
| 215 | Bad Authentication data |
项目性质
内部使用,私有,公有
PM的设计,研发同学的想法。
总结
不忘初衷!
快速溯源、简单易记、沟通标准化
最后
虽说编写代码是个非常有趣的过程,但要写出有灵魂的代码也需要一些指导思想,比如SOLID原则:
- SRP(单一职责原则)
- OCP(开闭原则)
- LSP(里氏替换原则)
- ISP(接口隔离原则)
- DIP(依赖反转原则)